How to filter a Pandas DataFrame
There is a filter method on Pandas DataFrame, but it is limited to only filtering on the labels on the index columns. There are multiple ways to filter a DataFrame to focus on the information required. This article demonstrates a number of ways to filter data in a DataFrame.
Comparing a DataFrame to be equal to a value with double equals ( == ) will
return a dataframe of boolean values set to true, where the values in the dataframe
equal the compare value. This boolean dataframe can be fed into the original
dataframe to return a dataframe with only the data that matched the compare value.
This is more useful when the comparison is on a single column.
Summary of methods to filter Pandas DataFrame:
Filtering data in Pandas DataFrame |
|
|---|---|
|
df[df['Rank'] == 16]
df[df['Rank'].eq(16)] |
Get rows in df that have a Rank equal to 16 |
|
df[df['Rank'] >= 16]
df[df['Rank'].ge(16)] |
Get rows in df that have a Rank greater than or equal to 16 |
|
df[df['Rank'] > 16]
df[df['Rank'].gt(16)] df[df['Rank'] != 16] df[df['Rank'].ne(16)] df[df['Rank'] < 16] df[df['Rank'].lt(16)] df[df['Rank'] <= 16] df[df['Rank'].le(16)] |
Other numeric comparison include
greater than Not equal to less than less than or equal to |
|
df[df['Name'] == 'JASMINE']
df[df['Name'].eq('JASMINE')] |
Get rows in df that have a Name equal to JASMINE |
| df[df['Name'].str.startswith('A')] | Get rows in df that have a Name that starts with A |
| df[df['Name'].str.endswith('A')] | Get rows in df that have a Name that ends with A |
| df[df['Name'].str.contains('AS')] | Get rows in df that have a Name that contains the letters 'AS' |
| df[df['Name'].str.contains('as', case=False)] | Get rows in df that have a Name that contains the letters 'as' ignoring case |
| df[df['Name'].str.contains('ian$|ine$', case=False, regex=True)] | Get rows in df that have a Name ending in 'ian' or 'ine' ignoring case |
| df[df['Name'].isin(['SOPHIA','PAUL'])] | Get rows in df that have a Name in a list of names |
| df[( (df['Name'].str.contains('A')) & (df['Year'] > 1980) & (df['Gender'] == 'Female') & (df['Count'] > 1500) )] | Get rows in df that have a Name containing the letter 'A' and have Gender Female with a count greater than 1500 and are after 1980 |
| df.filter(items=['Year', 'Name'], axis=1) | Use filter method to filter the dataframe to specified columns |
| df.filter(like='7', axis=0) | Filter DataFrame to index equal to a value |
| df.filter(regex='^5|8', axis=0) | Use filter method to filter the dataframe to indexes beginning with 5 or 8 |
Load sample data
We will use the most popular baby names from popular baby names. This dataset contains data for the top 25 baby names in California based on information entered on birth certificates.
Load the data directly from the website:
1url = "https://data.chhs.ca.gov/dataset/4a8cb74f-c4fa-458a-8ab1-5f2c0b2e22e3/resource/f3fe42ed-4441-4fd8-bf53-92fb80a246da/download/2021-06-18_topbabynames_1960-2019.csv"
2names_df = pd.read_csv(url)
Review the data:
1print(names_df.shape)
2names_df.head()
3
4(3003, 5)
5
6 Year Gender Rank Name Count
70 1960 Female 1 SUSAN 3299
81 1960 Female 2 MARY 3248
92 1960 Female 3 KAREN 3156
103 1960 Female 4 CYNTHIA 2982
114 1960 Female 5 LISA 2839
Trim the data to a sample set of 10 rows that will be used to demonstrate filtering dataframes.
1df = names_df.sample(n=10, random_state=1)
2df.reset_index(drop=True, inplace=True)

Sample dataframe of top baby names
Filter by numeric data in a column
A common field type to filter data on is a numeric field. It is possible to filter where the number is equal to a particular number or less than or greater than a number.
1df.dtypes
2
3"""
4Year int64
5Gender object
6Rank int64
7Name object
8Count int64
9"""
Selecting a column in a dataframe such as df['Rank'] returns a Pandas.Series,
which can be compared to a single number that will return a Pandas.Series of boolean
values.
1df['Rank'] == 16
2
3"""
40 False
51 False
62 False
73 False
84 False
95 False
106 False
117 True
128 True
139 False
14"""

DataFrame of booleans that match the criteria
The Pandas.Series of boolean values can then be used on the original DataFrame to return only the rows where the boolean values are true. Pandas DataFrame also has functions such as eq to perform element-wise comparison, similar to the logic comparisons such as ==.
All logic comparisons work in a similar way
| operator | function | description |
|---|---|---|
| == | eq | equal to |
| != | ne | not equal to |
| > | gt | greater than |
| >= | ge | greater than or equal to |
| < | lt | less than |
| <= | le | less than or equal to |
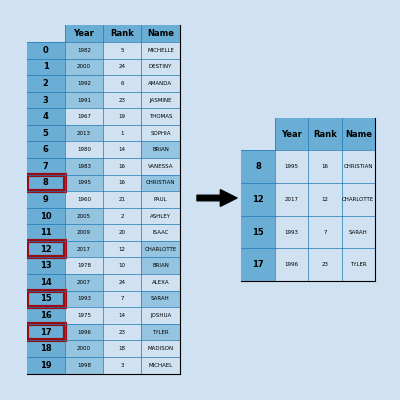
1df[df['Rank'] == 16]
2
3"""
4 Year Gender Rank Name Count
57 1983 Female 16 VANESSA 1517
68 1995 Male 16 CHRISTIAN 2761
7"""

Filter DataFrame on numeric value
Numeric data Greater Than
1df[df['Rank'] > 19]
2
3"""
4 Year Gender Rank Name Count
51 2000 Female 24 DESTINY 1188
63 1991 Female 23 JASMINE 1482
79 1960 Male 21 PAUL 2136
8"""

Filter DataFrame on numeric value - greater than
Numeric data Greater Than or Equal To
1df[df['Rank'] >= 19]
2
3"""
4 Year Gender Rank Name Count
51 2000 Female 24 DESTINY 1188
63 1991 Female 23 JASMINE 1482
74 1967 Male 19 THOMAS 2149
89 1960 Male 21 PAUL 2136
9"""

Filter DataFrame on numeric value - greater than or equal to
Filter by text in a column
Text fields can be filtered in a similar manner as the numeric fields.
1df[df['Name'] == 'JASMINE']
2
3"""
4 Year Gender Rank Name Count
53 1991 Female 23 JASMINE 1482
6"""

Filter DataFrame on Text value
Filter by partial text match in columns
Text comparison is case-sensitive and the logic operators compare the given text with
the text in the entire field for an exact match. The greater-than and less-than
operators work on text, but these are of limited use. Pandas.Series.str to the
rescue! The Pandas.Series.str has a number of string comparisons to allow filtering
dataframes on virtually anything. The use of pandas.Series.str.contains and
pandas.Series.str.match allows the use or regular expressions, but these may be
slower on larger dataframes. The contains function takes a boolean parameter for
regex and when set to False, treats the pattern as a literal string. The contains
function defaults to searching in a case-sensitive manner, but this can be changed
with the parameter case.
Filter on names starting with a letter
1df[df['Name'].str.startswith('A')]
2
3"""
4 Year Gender Rank Name Count
52 1992 Female 6 AMANDA 2776
6"""

Filter DataFrame on Text value - startswith
Filter on names ending with a letter
1df[df['Name'].str.endswith('A')]
2
3"""
4 Year Gender Rank Name Count
52 1992 Female 6 AMANDA 2776
65 2013 Female 1 SOPHIA 3447
77 1983 Female 16 VANESSA 1517
8"""

Filter DataFrame on Text value - endswith
Filter on names containing text
1df[df['Name'].str.contains('AS')]
2
3"""
4 Year Gender Rank Name Count
53 1991 Female 23 JASMINE 1482
64 1967 Male 19 THOMAS 2149
7"""

Filter DataFrame on Text value - contains
Match string ignoring case using the case parameter set to False.
1df[df['Name'].str.contains('as', case=False)]
2
3"""
4 Year Gender Rank Name Count
53 1991 Female 23 JASMINE 1482
64 1967 Male 19 THOMAS 2149
7"""

Filter DataFrame on Text value - contains, ignore case
The default for pandas.Series.str.contains is to use a regular expression. This
code searches for all names that end in either ian or ine. When the regex
parameter is set to False this does not match any names.
1df[df['Name'].str.contains('ian$|ine$', case=False, regex=True)]
2
3"""
4 Year Gender Rank Name Count
53 1991 Female 23 JASMINE 1482
66 1980 Male 14 BRIAN 2737
78 1995 Male 16 CHRISTIAN 2761
8"""
9
10df[df['Name'].str.contains('ian$|ine$', case=False, regex=False)]
11
12"""
13Empty DataFrame
14"""

Filter DataFrame on Text value - regex
Filter by multiple search criteria
Filtering on a single field is great. Filtering data can be even more powerful when combining different search criteria either on the same column or on multiple columns. This can get confusing as the number of conditions grow and it is worth noting that the conditions are applied to each row individually. As an example, suppose we want all the data for names 'SOPHIA' and 'PAUL'. We cannot look for data where name is 'SOPHIA' and where name is 'PAUL', as no individual row has both of these. Instead we need to look for data where name is 'SOPHIA' OR where name is 'PAUL'.
However, if it is an exact match on multiple values, it is better to use pandas.DataFrame.isin function - and it is easier to read.
1df[((df['Name'] == 'SOPHIA') | (df['Name'] == 'PAUL'))]
2
3df[df['Name'].isin(['SOPHIA','PAUL'])]
4
5"""
6 Year Gender Rank Name Count
75 2013 Female 1 SOPHIA 3447
89 1960 Male 21 PAUL 2136
9"""

Filter DataFrame on Text value - isin
Filter on all records where the name starts with "J" and ends in "INE".
1df[((df['Name'].str.startswith('J')) & (df['Name'].str.endswith('INE')))]
2
3"""
4 Year Gender Rank Name Count
53 1991 Female 23 JASMINE 1482
6"""

Filter DataFrame on Text value - startswith and endswith
Filter by multiple columns
Multiple search criteria can also be applied across multiple columns. This code filters on all rows where the "Name" contains the letter "A" and the "Year" is after 1980 and the "Gender" is "Female" and the "Count" is greater than 1,500. The conditions are enclosed in braces and spread out on multiple lines to make the conditions easier to read. The filtered data will only contain rows where all of these conditions are met.
1df[(
2 (df['Name'].str.contains('A'))
3 & (df['Year'] > 1980)
4 & (df['Gender'] == 'Female')
5 & (df['Count'] > 1500)
6 )]
7
8"""
9 Year Gender Rank Name Count
102 1992 Female 6 AMANDA 2776
115 2013 Female 1 SOPHIA 3447
127 1983 Female 16 VANESSA 1517
13"""

Filter DataFrame on multiple columns
Filter the full names dataset
Filter on all of the Male names ending in "R" in the top ten names after the year 1990.
1names_df[(
2 (names_df['Name'].str.endswith('R'))
3 & (names_df['Year'] > 1990)
4 & (names_df['Gender'] == 'Male')
5 & (names_df['Rank'] < 10)
6 )]
7
8"""
9 Year Gender Rank Name Count
101577 1991 Male 2 CHRISTOPHER 5672
111628 1992 Male 3 CHRISTOPHER 5102
121679 1993 Male 4 CHRISTOPHER 4600
131729 1994 Male 4 CHRISTOPHER 4172
141779 1995 Male 4 CHRISTOPHER 4013
151830 1996 Male 5 CHRISTOPHER 3896
161880 1997 Male 5 CHRISTOPHER 3680
171934 1998 Male 9 CHRISTOPHER 3386
181984 1999 Male 9 CHRISTOPHER 3237
192033 2000 Male 8 CHRISTOPHER 3311
202334 2006 Male 9 CHRISTOPHER 2869
212382 2007 Male 7 CHRISTOPHER 2978
222431 2008 Male 6 ALEXANDER 2865
232434 2008 Male 9 CHRISTOPHER 2607
242480 2009 Male 5 ALEXANDER 2875
252529 2010 Male 4 ALEXANDER 2593
262581 2011 Male 6 ALEXANDER 2454
272632 2012 Male 7 ALEXANDER 2415
282682 2013 Male 7 ALEXANDER 2374
292731 2014 Male 5 ALEXANDER 2485
302783 2015 Male 6 ALEXANDER 2304
312834 2016 Male 7 ALEXANDER 2218
322886 2017 Male 9 ALEXANDER 1998
332935 2018 Male 8 ALEXANDER 1908
342984 2019 Male 7 ALEXANDER 1838
35"""
Filter using Filter method
The filter method on Pandas DataFrame is limited to only filtering on the index
column names. This is of limited use, but it does support filtering on regex. The
filter method can take 4 parameters but items, like, or regex are mutually
exclusive. Using Filter can be useful when the field of interest is the index or can
be set as the index of the DataFrame.
Filter on columns in the list.
1df.filter(items=['Year', 'Name'], axis=1)
2
3"""
4 Year Name
50 1982 MICHELLE
61 2000 DESTINY
72 1992 AMANDA
83 1991 JASMINE
94 1967 THOMAS
105 2013 SOPHIA
116 1980 BRIAN
127 1983 VANESSA
138 1995 CHRISTIAN
149 1960 PAUL
15"""

Filter columns on DataFrame
Filter where the index is 7.
1df.filter(like='7', axis=0)
2
3"""
4 Year Gender Rank Name Count
57 1983 Female 16 VANESSA 1517
6"""

Filter DataFrame on Index equal to 7
Filter where the index begins with 5 or 8 using regex.
1df.filter(regex='^5|8', axis=0)
2
3"""
4 Year Gender Rank Name Count
55 2013 Female 1 SOPHIA 3447
68 1995 Male 16 CHRISTIAN 2761
7"""

Filter DataFrame with regex on index
Conclusion
It is easy to filter data in a Pandas DataFrame, but the filter method may not be the method you are looking for! If you are familiar with SQL, you may find the where method, but this is not used for filtering in Pandas as discussed in "Pandas - Dataframe Where function".
Filtering data in DataFrames is done by matching criteria on a particular column in the DataFrame and feeding the boolean Data Series into the original DataFrame to filter out where there is not a match. This sounds more complicated than it is and this article showed some basic examples of filtering on numeric data and text data.